Expresiones
regulares
Una expresión regular es un modelo o una forma de
comparar con una cadena de caracteres. Esta comparación es conocida con
el nombre de pattern matching o reconocimiento de
patrones, permite identificar las ocurrencias del modelo en los datos tratados.
La utilización principal de las expresiones regulares en Perl consiste en
la identificación de cadenas de caracteres para la búsqueda
modificación y extracción de palabras clave. De esta manera se pueden dividir las expresiones regulares en varios
tipos que son: expresiones regulares de sustitución, expresiones
regulares de comparación y expresiones regulares de
traducción.
1. Expresiones
regulares de comparación.
Nos permiten evaluar si un patrón de
búsqueda se encuentra en una cadena de caracteres, de modo que mediante
este tipo de expresiones regulares obtendremos un valor lógico verdadero
o falso según se encuentre el patrón deseado. La sintaxis de este
tipo de expresiones regulares es la siguiente:
valor a comparar =~ patrón de búsqueda
He aquí un ejemplo:
#
imprimimos todas las líneas que contengan "html". Ej.:
"htmlexe"
if ($linea =~ /html/) {
print $linea;
}
Los
patrones de búsqueda pueden integrar información relativa al
contexto, tal como la búsqueda de líneas que empiecen por la
cadena de caracteres, la extracción de palabras que tengan prefijos o
sufijos particulares... Estos contextos se tienen mediante una
representación particular del modelo. Esta representación se
explica en los siguientes apartados:
1.1. Patrones definidos
por una clase de caracteres.
A menudo resulta práctico extraer las palabras
que contienen una cifra, una vocal, o caracteres de control particulares. El
modelo así definido no se indica por un carácter particular
sino por un clase de caracteres mediante el operador [ ]. He aquí
algunas posibles construcciones:
[aeiou] # Cualquier vocal
[0-9] #
Cualquier número del 0 al 9.
[0123456789] # Igual [0-9]
[0-9a-z] # Cualquier letra o
cualquier numéro
[\~\@;:\^_] # Cualquiera de los
caracteres(~,@,;,:^,_)
Generalmente de puede definir una clase de caracteres valiéndose
de la complementaria. Ésta se expesifica mediante la sintaxis [^ ].
Siendo el símbolo ^ el que representa la negación de los
caracteres o clase de caracteres consecutivos:
[^0-9] #
Carácter que no sea un dígito
La definición del patrón por clase se contempla
con un conjunto de caracteres de control. Estos facilitan la
definición de modelos complejos en rutinas de comparación.
Estos facilitan la definición de patrones complejos en rutinas de
comparación. La siguiente tabla representa estas extenciones:

Por otro lado, decir que los símbolos \n, \r,
\f y \t tienen su significado habitual, es decir, significan nueva
línea, retorno de carro, salto de página y tabulación
respectivamente.
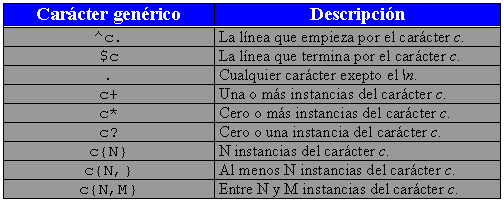
A continuación veremos otra lista de
caracteres genéricos que aumentarán la flexibilidad en la
contrucción de patrones de búsqueda. Estos caracteres se
muestran en la siguiente tabla:
1.2. Referencia de patrones.
Se utilizán para referenciar patrones en
las expresiones regulares. Perl trabaja con dos tipos de operadores de
comparación:
- $1,$2,...,$9.
Sirven para referenciar uno de los patrones de búsqueda
de la expresión regular. El número del 1 al 9 representa
el patrón al que queremos referirnos dentro de la
expresión regular. Así un ejemplo del uso de este operador
se puede observar en este código en Perl que añade el
articulo 'El' a un nombre común: (en este
ejemplo se utilizará una expresión regular de
sustitución que veremos en el siguiente apartado).
$var = "coche";
$var =~ s/(coche)/El $1/; # $1 equivale a coche
print $var;
- \1,\2,...,\9.
Este operador tiene la misma utilidad que el anterior se
utiliza para referenciar patrones, pero esta vez la referencia se ha de
producir dentro de la expresión regular. He aquí un
ejemplo:
if ($var =~ (/^(\w)+.*\1$/) {
print $var;
}
Esta expresión regular
de comparación tiene el siguiente significado: mediante la cadena
^(\w)+ nos referimos a todos los caracteres alfanuméricos que
forman parte del principio de la cadena contenida en $var, es decir, la
cadena ha de empezar por uno o más caracteres
alfanuméricos. Con la cadena .* referenciamos un conjunto
arbitrario de caracteres de longitud desconocida, finalmente con la
cadena \1 expresamos el primer patrón utilizado y con $
significamos que este patrón debe de estar al final de la cadena
contendia en $var. En definitiva la expresión regular
tomará el valor verdadero, cuando la cadena de caracteres
contenida en $var tenga la misma cadena de caracteres
alfanuméricos al principio y al final. Así por ejemplo, si
$var tiene una cadena de caracteres como esta: 'hola juansdfa hola' el
valor de la expresión regular será cierto, ya que los
espacios en blanco no se consideran caracteres alfanuméricos.
1.3. Utilización de carácteres
reservados.
En la especificación del modelo, cada
carácter se interpreta para determinar las ocurrencias en los datos.
Sin embargo, los caracteres siguientes:
+
? . * ^ $ ( ) [ ] { } | & \
son
reservados por el lenguaje y deben ir precedidos por el símbolo de
barra inversa \. Esto permita ignorar su especificidad y considerar los como
un carácter cualquiera. Por ejemplo:
#
busca ocurrencia de "ford" en $car
$marca = "ford";
if ($car =~
/$marca/) {
print $car;
}
#
busca ocurrencia de "$marca" en $car
if ($car =~ /\$marca/) {
print
$car;
}
1.4. Combinación de expresiones
regulares.
Se realiza con los operadores | y & que equivalen
al or y al
and
lógico respectivamente. Por ejemplo, con el operador | podemos
representar una lista de alternativas, es decir:
if ($car =~ /ford | audi/) {
print $car;
}
mientras que con el operador & exigimos que la variable contenga
las dos expresiones regulares propuestas:
if ($direccion =~ /calle & piso/) {
print $direccion;
}
2. Expresiones
regulares de sustitución.
Las
expresiones regulares de sustitución permiten cambiar los patrones de
búsqueda por caracteres nuevos definidos por el usuario que componen el
patrón de sustitución, la sintaxis es la siguiente:
valor a sustituir =~ s/patrón de búsqueda/patrón de
sustitución/opciones
Las opciones las
podemos ver en la siguiente tabla:

A
continución vamos a ver unos ejemplos para aclarar su manejo:
$var
= 'abc123yz';
$var =~
s/d+/$&*2/e;
# $var = 'abc246yz'
$var =~
s/d+/sprintf("%5d",$&)/e; # $var = 'abc 246yz'
$var =~ s/\w/$& x
2/eg; # $var =
'aabbccc 224466yyzz'
Nota: Como veremos en el capítulo
10 con más profundidad, $& es una variable
predefinida por el lenguaje que contiene el valor de la última cadena
de caracteres comparada exitosamente.
3. Expresiones
regulares de traducción.
Este
tipo de expresiones regulares tienen una manera de trabajar muy parecida a la de
las sustituciones. En este caso se trata de comparar uno a uno los caracteres
del patrón de búsqueda con los de la cadena de sustitución,
de modo que cada vez que se encuentra una ocurrencia que coincide con uno de los
caracteres del patrón se intercambia por su correspondiente en la cadena
del patrón de sustitución. La sintaxis general de esta expresion
regular es la siguiente:
variable =~ tr/patrón de búsqueda/cadena a traducir/opciones
Las opciones las podemos ver en la siguiente tabla:

También decir que este operador
devuelve el número de reemplazados o borrados. He aquí algunos ejemplos que
nos servirán para tener una manejo:
$var =~ tr/A-Z/a-z/; #
transforma mayúsculas a minúsculas
$cnt = $var =~ tr/*/*/;
# cuenta los arteriscos de $sky
$cnt = $var =~ tr/0-9//;# cuenta y
suprime las cifras de $sky
$var =~ tr/a-zA-z//s; # elimina
duplicados. bbookk -> bok
$var =~ tr/a-zA-z/ /cs;
# cambia los
caracteres no alfabéticos en espacios y elimina duplicados
4.
Ejemplo.
Seguro
que ha estas alturas todavía no se tiene claro la diferencia entre los
distintos tipos de expresiones regulares, para aclarar el concepto introducimos
los siguientes ejemplos:
En
primer lugar vemos una expresión regular de búsqueda que
dará cierto si en la variable $copia se encuentra el
patroón copia. Si es así, como veremos se imprimirá
un mensaje.
$copia = "copy, xcopy, diskcopy";
if ($copia =~
/copy/) {
print "Encontrada la cadena copy";
}
A continuación viene un ejemplo de
expresión regular de sustitución:
$copia ="copy, xcopy, diskcopy";
$copia =~ s/copy/copia/g;
Esta operación reemplaza todas las
ocurrencias de copy por copia quedando:
"copia, xcopia, diskcopia"
En último lugar realizaremos un ejemplo
con una expresión regular de traducción:
$copia = "copy, xcopy, diskcopy";
$copia =~ tr/copy/12345/;
Como se ve en este caso, se sustituye cade
ocurrecia de 'c' por 1, de 'o' por 2, de 'p' por 3 y de 'y' por 4. El
carácter de traducción 5 es ignorado puesto que no tiene ninguna
correspondencia con ninguno de los caracteres de patrón. Por tanto, el
contenido de la variable $copia será:
"1234, x1234, disk1234"
Otro caso podría ser el
siguiente:
$copia = "copy, xcopy, diskcopy";
$copia =~ tr/copy/123/;
Este ejemplo es
idéntico a el anterior pero en este caso sólo tenemos dos
caracteres en la cadena de traducción. Así, cuando el
número de caracteres en la cadena de traducción es menor que el
número de caracteres del patrón, las ocurrencia de los caracteres
del patrón que no tienen correspondencia con ningún caracter de
traducción, son intercambiados por el último de los caracteres de
traducción. Por tanto, el contenido de la variable $copia
será:
"1233, x1233,
disk1233"



